FDA Project - Part 2
Challenge
We have arrived at a workable dataset, but the most important part for text-analysis is inside the MDR_Text field. Each MDR_Text item is a list of narratives pertaining to the specific malfunction report. We can try to unnest these lists of narratives and keep each narrative separate, but that is not necessary for the scope of this project–instead, what is needed is to remove punctuation and unnecessary/redundant words, so that we have a short string of unique words in each MDR Text field. This will allow for counting of keywords and the compilation of useful visualizations.
An example of one such visualization is shown below. Created in Tableau from output from this code, it shows the progression of keywords of Heartvalve malfunction reports over the past two years.
Code
First we need to cull out unneeded columns and perform some minor data cleaning.
#Keep only relevant columns
dfmain = dfmain[["_device_report_product_code","_brand_name","_generic_name","_manufacturer_d_name","type_of_report","report_number","report_source_code",
"date_received","event_type","mdr_text"]]
#Rename columns
dfmain.columns = ["product_code","brand_name","generic_name","manufacturer_name","type_of_report","report_number",
"report_source_code","date_received","event_type","mdr_text"]
#Update date column to date format
dfmain["date_received"] = pd.to_datetime(dfmain["date_received"])
#Remove brackets from type of report column
dfmain['type_of_report'] = dfmain['type_of_report'].str.join(', ')
#Update MDR Text to only show the text narrative items--also lowercase the text
newmdr = []
for text_index in dfmain["mdr_text"]:
newmdr.append(''.join(re.findall("'text': .+?}",str(text_index))).translate(str.maketrans('', '', string.punctuation)).replace("text"," - ")[4:])
dfmain["mdr_text"] = [x.lower() for x in newmdr]
dfmain.head()
| product_code | brand_name | generic_name | manufacturer_name | type_of_report | report_number | report_source_code | date_received | event_type | mdr_text | |
|---|---|---|---|---|---|---|---|---|---|---|
| 98596 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00003 | Manufacturer report | 2020-02-06 | Malfunction | investigation for this complaint is currently ... |
| 17151 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission | 3004068499-2020-00004 | Manufacturer report | 2020-02-27 | Malfunction | patient information does not apply the device ... |
| 42763 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00001 | Manufacturer report | 2020-02-06 | Malfunction | investigation for this complaint is currently ... |
| 70387 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00002 | Manufacturer report | 2020-02-06 | Malfunction | investigation for this complaint is currently ... |
| 20329 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission | 3004068499-2020-00005 | Manufacturer report | 2020-03-20 | Malfunction | patient information does not apply the device ... |
Here comes much of the NLP operations. We unnest each sentence and perform lemmatization in order to standardize suffixes. We also remove stop-words and a manually curated list of words that are very common and/or not useful for the analysis. At this point it is a manual operation to gather these words–in the future, it would be beneficial to gather them for exclusion more automatically, perhaps with IPV/SV analysis.
#Remove NA items
dfmain.fillna('', inplace=True)
#Prepare for lemmatization
lemmatizer = nltk.stem.WordNetLemmatizer()
wordnet_lemmatizer = WordNetLemmatizer()
#Create function to tag words with what part of speech they are
def nltk_tag_to_wordnet_tag(nltk_tag):
if nltk_tag.startswith('J'):
return wordnet.ADJ
elif nltk_tag.startswith('V'):
return wordnet.VERB
elif nltk_tag.startswith('N'):
return wordnet.NOUN
elif nltk_tag.startswith('R'):
return wordnet.ADV
else:
return None
#Create function to separate strings into words, assign parts of speech, and lemmatize accordingly
def lemmatize_sentence(sentence):
#tokenize the sentence and find the POS tag for each token
nltk_tagged = nltk.pos_tag(nltk.word_tokenize(sentence))
wordnet_tagged = map(lambda x: (x[0], nltk_tag_to_wordnet_tag(x[1])), nltk_tagged)
lemmatized_sentence = []
for word, tag in wordnet_tagged:
if tag is None:
#if there is no available tag, append the token as is
lemmatized_sentence.append(word)
else:
#else use the tag to lemmatize the token
lemmatized_sentence.append(lemmatizer.lemmatize(word, tag))
return " ".join(lemmatized_sentence)
#Perform Lemmatization - this step can take some time
dfmain['mdr_text'] = dfmain['mdr_text'].apply(lambda x: lemmatize_sentence(x))
#Remove stop words
stop_words = set(stopwords.words('english'))
#Add additional common words into stopwords
stop_words.update(["investigation","still","progress","complete","supplemental","report","filed","device","returned","reported",
"-","due","failure","failed","may","ensure","assures","around","met","reports","number","per","dated","patient",
"conclusion","performed","year","years","therefore","submitted","information","received","upon","event",
"events","review","required","appropriate","monitored","monitor","basis","continue","monthly","trends","completion",
"additional","months","yet","without","history","regarding","cause","record","established","accordingly","procedure",
"provided","underwent","reason","evaluation","time","related","product","severed","post","return","made","also",
"andor","multiple","remains","determined","replacement","definitive","issues","however","clinical","factors",
"effects","release","identified","cannot","reviewed","would","including","available","issued","observation",
"common","action","regard","make","future","severe","issue","require","receive","month","submit","occur",
"factor","include","provide","remain","contribute","establish","relate","effect","replace","analysis","via",
"perform","subject","likely"])
dfmain = dfmain[dfmain['mdr_text'].notnull()]
dfmain['mdr_text'] = dfmain['mdr_text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop_words)]))
dfmain.head()
| product_code | brand_name | generic_name | manufacturer_name | type_of_report | report_number | report_source_code | date_received | event_type | mdr_text | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LWR | PERCEVAL SUTURELESS AORTIC HEART VALVE | TISSUE HEART VALVE | LIVANOVA CANADA CORP. | Initial submission, Followup, Followup | 1718850-2020-01047 | Distributor report | 2020-03-20 | Injury | manufacturer notify serious adverse involve pe... |
| 1 | DYE | CARPENTIER-EDWARDS PERIMOUNT MAGNA MITRAL EASE... | REPLACEMENT HEART VALVE | EDWARDS LIFESCIENCES | Initial submission, Followup, Followup | 2015691-2020-10062 | Manufacturer report | 2020-01-07 | Injury | although bioprosthetic valve prove excellent l... |
| 2 | DYE | INSPIRIS RESILIA AORTIC VALVE | REPLACEMENT HEART VALVE | EDWARDS LIFESCIENCES | Initial submission, Followup, Followup, Follow... | 2015691-2020-10677 | Manufacturer report | 2020-02-25 | Injury | udi b4 stenosis develop progressively addition... |
| 3 | DYE | CARPENTIER-EDWARDS PERIMOUNT MAGNA EASE PERICA... | REPLACEMENT HEART VALVE | EDWARDS LIFESCIENCES | Initial submission, Followup | 2015691-2020-10709 | Manufacturer report | 2020-02-27 | Injury | stenosis regurgitation develop progressively a... |
| 4 | MWH | CONTEGRA | CONDUIT,VALVED,PULMONIC | MEDTRONIC HEART VALVE DIVISION | Initial submission, Followup | 2025587-2020-00676 | Manufacturer report | 2020-03-05 | Injury | medtronic 8 9 implant 18mm pulmonary valved co... |
In order to create a bar chart race for keywords, we need to remove all duplicate words from each MDR_Text field.
no_dup = []
#Following function found from internet
def remove_duplicates(input):
# split input string separated by space
input = input.split(" ")
# now create dictionary using counter method
# which will have strings as key and their
# frequencies as value
UniqW = Counter(input)
# joins two adjacent elements in iterable way
s = " ".join(UniqW.keys())
return (s)
dfmain['mdr_text_nodup'] = dfmain['mdr_text'].apply(remove_duplicates)
dfmain['mdr_text_nodup'] = dfmain['mdr_text_nodup'].map(str)
dfmain.head()
| product_code | brand_name | generic_name | manufacturer_name | type_of_report | report_number | report_source_code | date_received | event_type | mdr_text | mdr_text_nodup | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 98596 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00003 | Manufacturer report | 2020-02-06 | Malfunction | complaint currently underway yet completed fol... | complaint currently underway yet completed fol... |
| 17151 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission | 3004068499-2020-00004 | Manufacturer report | 2020-02-27 | Malfunction | patient information apply patient contact capa... | patient information apply contact capab4 initi... |
| 42763 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00001 | Manufacturer report | 2020-02-06 | Malfunction | complaint currently underway yet completed fol... | complaint currently underway yet completed fol... |
| 70387 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00002 | Manufacturer report | 2020-02-06 | Malfunction | complaint currently underway yet completed fol... | complaint currently underway yet completed fol... |
| 20329 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission | 3004068499-2020-00005 | Manufacturer report | 2020-03-20 | Malfunction | patient information apply patient contact outc... | patient information apply contact outcomes att... |
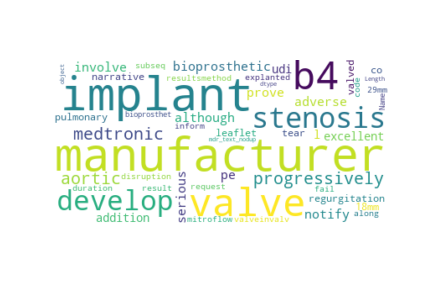
At this point we can run a basic word cloud and see, from the total dataset, what words show up most.
#Implement Word Cloud
word_cloud = WordCloud(collocations = False, background_color = 'white').generate(str(dfmain["mdr_text_nodup"]))
plt.imshow(word_cloud, interpolation='bilinear')
plt.axis("off")
plt.savefig('foo.png')
plt.show()
#Create new date field with the days removed, for visualizations
dfmain["year"] = pd.to_datetime(dfmain["date_received"], format = '%Y-%m-%d').dt.year
dfmain["month"] = pd.to_datetime(dfmain["date_received"], format = '%Y-%m-%d').dt.month
dfmain["plaindate"] = pd.to_datetime(dfmain[['year', 'month']].assign(DAY=1))
dfmain = dfmain.drop(["year","month"], 1)
dfmain.head()
| product_code | brand_name | generic_name | manufacturer_name | type_of_report | report_number | report_source_code | date_received | event_type | mdr_text | mdr_text_nodup | plaindate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 98596 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00003 | Manufacturer report | 2020-02-06 | Malfunction | complaint currently underway yet completed fol... | complaint currently underway yet completed fol... | 2020-02-01 |
| 17151 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission | 3004068499-2020-00004 | Manufacturer report | 2020-02-27 | Malfunction | patient information apply patient contact capa... | patient information apply contact capab4 initi... | 2020-02-01 |
| 42763 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00001 | Manufacturer report | 2020-02-06 | Malfunction | complaint currently underway yet completed fol... | complaint currently underway yet completed fol... | 2020-02-01 |
| 70387 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission, Followup | 3004068499-2020-00002 | Manufacturer report | 2020-02-06 | Malfunction | complaint currently underway yet completed fol... | complaint currently underway yet completed fol... | 2020-02-01 |
| 20329 | KDN | LIFEPORT KIDNEY TRANSPORTER SYSTEM | PERFUSION CIRCUIT | ORGAN RECOVERY SYSTEMS, INC. | Initial submission | 3004068499-2020-00005 | Manufacturer report | 2020-03-20 | Malfunction | patient information apply patient contact outc... | patient information apply contact outcomes att... | 2020-03-01 |
#Create new dataframe--list of unique words in data, separated by month
dfmain['mdr_text_nodup'] = dfmain['mdr_text_nodup'].map(str)
dfword = pd.DataFrame()
#Create unique list of dates to be used in the for loop
datelist = dfmain["plaindate"].unique()
#Loop to create dataframe of unique words and the number of times they each appear
wordnumbers = []
for date_index in datelist:
wordnumbers = Counter(' '.join(map(lambda l: ''.join(l), dfmain.loc[dfmain["plaindate"] == date_index]["mdr_text_nodup"])).split(" "))
dftemp = pd.DataFrame.from_dict(wordnumbers, orient='index').reset_index()
dftemp["Date"] = date_index
dfword = pd.concat([dfword, dftemp])
dfword.columns = ["word","counts","date"]
#Add column for % representation of each word during their time period
def percentcalc(countcol, datecol):
perc = 0
#perc = countcol / 100
perc = countcol / len(dfmain[dfmain["plaindate"] == datecol])
return perc
dfword["percent"] = dfword.apply(lambda x: percentcalc(x['counts'],x['date']), axis = 1)
Now a new column is added to show the change from month to month for the counts of each word. This was a challenge to do in a way that was not too time-intensive. Instead of trying to search for each previous month’s value in the dataframe and then performing the subtraction calculation, we sort the dataset by word and then by date, and go through each item, checking to see if the previous line matches what we expect the word and previous date values to be. If these both match, the two counts values are subtracted, but if they do not match then the current value must be the “change” value we are looking for. This way we only go through the dataframe a single time, instead of once for each row in the dataset.
Several different searching methods were tried, but this was by far the fastest method.
#Begin by sorting the dataset and removing a leftover junk column
dfword = dfword.sort_values(["word","date"]).reset_index()
dfword.pop("index")
#Create a function to get the previous month off of a given string
def getlastmonth(dateinquestion):
newdate = dateinquestion[5:7]
newdate = int(newdate) - 1
if newdate == 0:
newdate = 12
newdate = str(newdate)
if len(newdate) == 1:
newdate = "0" + newdate
newdate = dateinquestion[0:4] + "-" + newdate + dateinquestion[7:10]
if newdate[5:7] == "12":
newmonth = str(int(newdate[0:4]) - 1)
newdate = newmonth + "-" + newdate[5:7] + dateinquestion[7:10]
return newdate
#Create a function to check if the previous row in the dataset is the actual previous month for the word in question,
#and then perform the subtraction if necessary to arrive at the change value
def previous_values(indexitem):
if indexitem > 0:
if (dfword["date"][indexitem-1] == getlastmonth(dfword["date"][indexitem])) & (dfword["word"][indexitem-1] == dfword["word"][indexitem]):
return (dfword["counts"][indexitem] - dfword["counts"][indexitem-1])
else:
return dfword["counts"][indexitem]
else:
return dfword["counts"][indexitem]
#Create the new column with the change value
dfword["change"] = dfword.apply(lambda x: previous_values(x.name), axis = 1)
| word | counts | date | percent | change | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2011-03-01 | 0.006536 | 1 |
| 1 | 0 | 1 | 2012-03-01 | 0.005848 | 1 |
| 2 | 0 | 2 | 2012-05-01 | 0.012658 | 2 |
| 3 | 0 | 1 | 2013-05-01 | 0.009709 | 1 |
| 4 | 0 | 1 | 2013-06-01 | 0.007812 | 0 |
dfword.to_csv(r'word.csv', index = False)
The end result is a csv file that can be imported into Tableau and turned into the bar chart race shown at the beginning of this post.